El Informe Internacional de Seguridad de la IA 2026 es una de las revisiones más completas hasta la fecha sobre los riesgos que plantean los sistemas de IA de propósito general. Ha sido elaborado por más de 100 expertos independientes de más de 30 países y demuestra que, si bien los sistemas de IA están funcionando a niveles que parecían ciencia ficción hace solo unos años, los riesgos de uso indebido, mal funcionamiento y daños sistemáticos y transfronterizos son claros.
Plantea un argumento convincente a favor de una mejor evaluación, transparencia y mecanismos de protección. Pero una pregunta directa sigue sin explorarse lo suficiente: ¿qué significa “seguro” cuando la IA opera de forma autónoma contra sistemas reales?
Un resumen de las conclusiones interesantes del Informe Internacional de Seguridad de la IA incluye:
- Al menos 700 millones de personas utilizan sistemas de IA semanalmente, con tasas de adopción más rápidas que las del ordenador personal en sus primeros años.
- Varias empresas de IA lanzaron sus modelos de 2025 con medidas de seguridad adicionales después de que las pruebas previas al despliegue no lograran descartar que los sistemas pudieran ayudar a no expertos a desarrollar armas biológicas. (!!!) (No está claro si la medida de seguridad adicional lo evitaría por completo)
- Los equipos de seguridad han documentado herramientas de IA siendo utilizadas en ciberataques reales tanto por actores independientes como por grupos patrocinados por estados.
El informe aborda en detalle los enfoques para gestionar muchos de los riesgos asociados con la IA– esta es nuestra opinión:
Dónde Aikido está de acuerdo con el informe (y cómo podría ir más allá)
1. La defensa por capas es importante
El informe describe un enfoque de defensa en profundidad para la seguridad de la IA, dividiéndolo en tres capas: construir modelos más seguros durante el entrenamiento, añadir controles en el despliegue y monitorizar los sistemas una vez que están en producción. Estamos de acuerdo en general con la aplicación de estas capas.
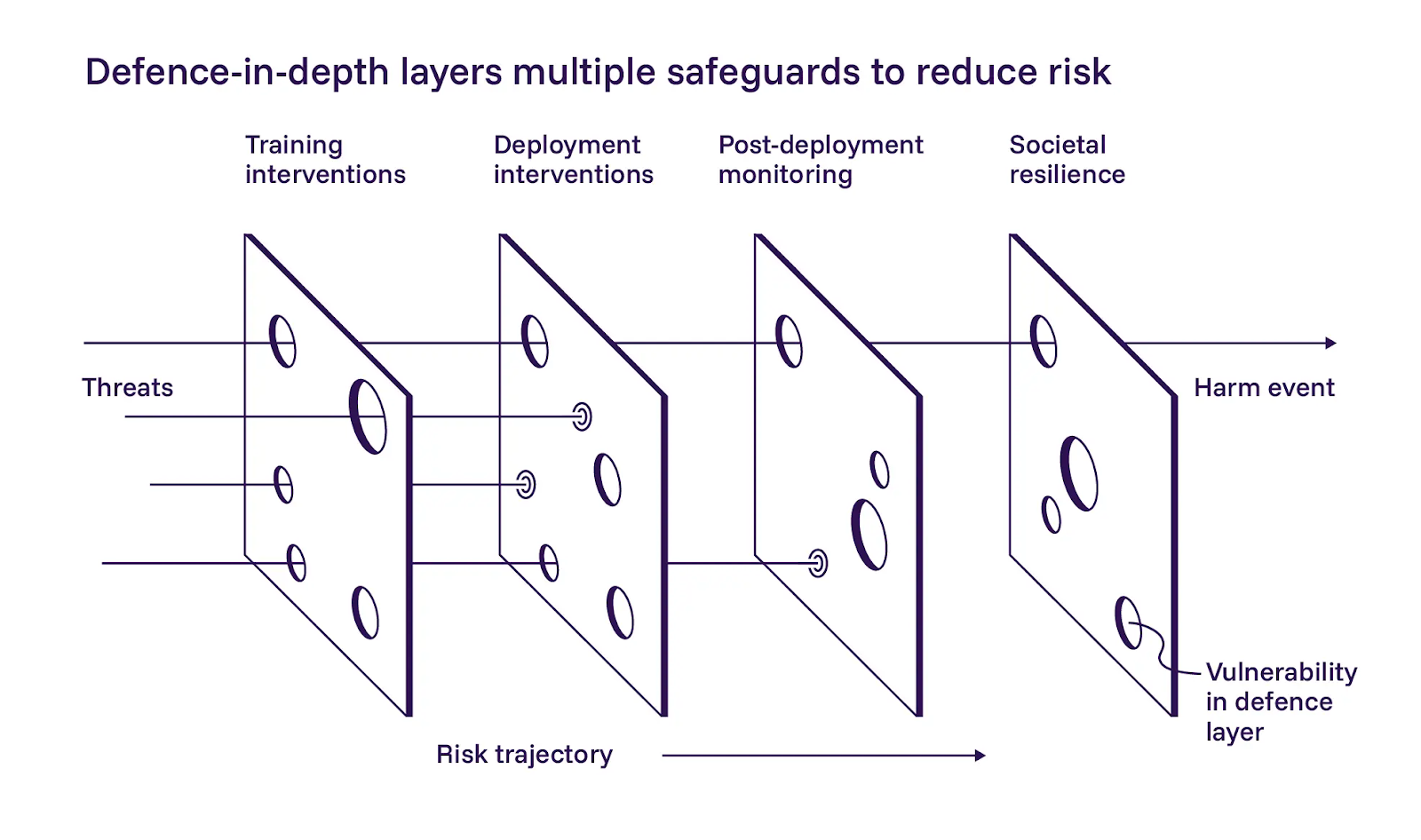
El informe enfatiza la primera capa, el desarrollo de modelos más seguros. Son cautelosamente optimistas de que las mitigaciones basadas en el entrenamiento pueden ayudar, pero también reconocen que son difíciles de implementar a escala. Aunque estamos de acuerdo en que los operadores de IA deben esforzarse al máximo durante el entrenamiento, nuestra filosofía difiere ligeramente del informe en este caso. No podemos depender de prompts o instrucciones para mantener los sistemas agenciales dentro del alcance. La defensa por capas solo funciona si cada capa puede fallar de forma independiente.
2. La validación como requisito de seguridad
El informe no profundiza en los detalles de implementación para la segunda capa, los controles en tiempo de despliegue, pero creemos que es aquí donde se puede lograr el progreso más inmediato.
El Informe Internacional documenta cómo los modelos manipulan sus evaluaciones de formas preocupantes. Algunos encuentran atajos que obtienen buenas puntuaciones en las pruebas sin resolver realmente el problema subyacente (reward hacking). Otros, intencionadamente, rinden por debajo de sus capacidades cuando detectan que están siendo evaluados, intentando evitar restricciones que las puntuaciones altas podrían activar (sandbagging). En ambos casos, los modelos optimizan para algo distinto del objetivo previsto.
Llegamos a la misma conclusión: una vez que los sistemas de IA operan de forma autónoma, no se puede confiar en lo que auto-informan, en sus niveles de confianza o en sus trazas de razonamiento. Un agente que valida sus propios descubrimientos crea un único punto de fallo disfrazado de redundancia. Una operación segura requiere tratar los hallazgos iniciales como hipótesis, reproducir el comportamiento antes de informar y utilizar una lógica de validación separada del descubrimiento. Esta validación puede incluso provenir de otro agente de IA.
3. Reducir el riesgo antes de permitir que los agentes operen en entornos reales
La tercera capa del informe cubre la observabilidad, los controles de emergencia y la monitorización continua después de que los sistemas entren en funcionamiento. Esto se alinea con lo que hemos observado en nuestras operaciones.
La operación de caja negra no es aceptable para sistemas autónomos que interactúan con infraestructura de producción, por lo que consideramos los mecanismos de parada de emergencia como requisitos no negociables. Si no puedes ver lo que hace un agente o detenerlo cuando se descontrola, no lo estás operando de forma segura, independientemente de lo bueno que sea el modelo subyacente.
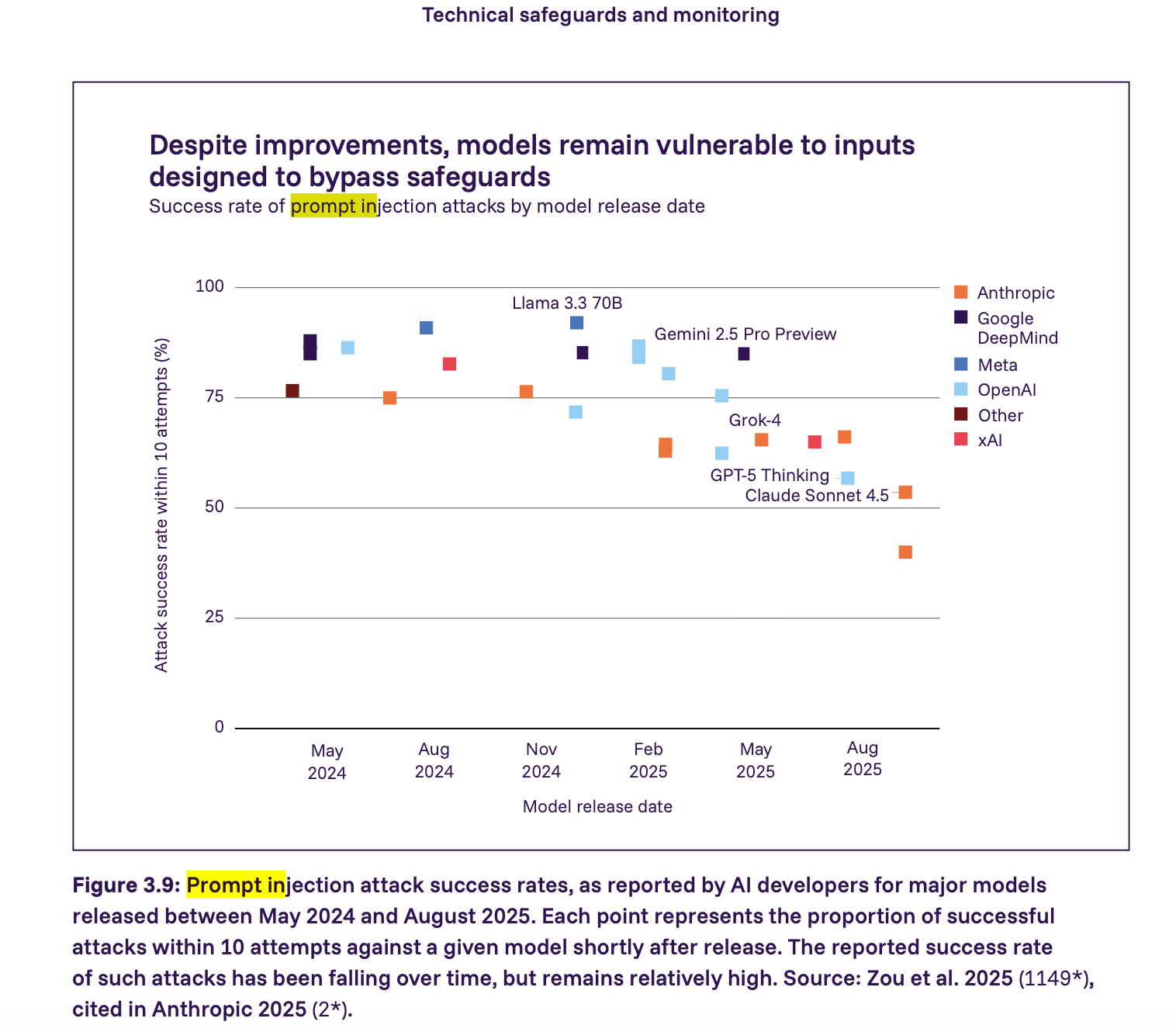
4. La inyección de prompts requiere restricciones impuestas, no esperanza
El informe muestra que los ataques de inyección de prompts siguen siendo una vulnerabilidad grave– muchos modelos importantes en 2025 podrían ser atacados con éxito mediante inyección de prompts con relativamente pocos intentos. La tasa de éxito está disminuyendo, pero sigue siendo relativamente alta. Vamos un paso más allá que el informe y sostenemos que cualquier agente que interactúe con contenido de aplicación no confiable debe considerarse vulnerable a la inyección de prompts por defecto. La seguridad, en este contexto, proviene de imponer restricciones y no de esperar que los modelos se comporten correctamente.
Lo que creemos que debería venir a continuación
Sistemas, no solo modelos
El informe argumenta sólidamente a favor de la defensa en profundidad, la transparencia y la evaluación. Estos son importantes, pero muchos de los problemas más inmediatos surgen cuando los modelos se conectan a herramientas, credenciales y entornos en vivo. Por eso los requisitos a nivel de implementación son tan importantes (y necesarios). Tenemos que traducir estos principios en requisitos técnicos concretos que los equipos puedan implementar.
Basándonos en la operación de sistemas de pentesting de IA en producción, creemos que los requisitos mínimos de seguridad para los sistemas de IA autónomos deberían incluir:
- Prevención de abusos y validación de la propiedad
- Control de alcance aplicado a nivel de red
- Aislamiento entre razonamiento y ejecución
- Observabilidad completa y controles de emergencia
- Residencia y garantías de procesamiento de datos
- Contención de inyección de prompts
- Validación y control de falsos positivos
Descubrimos que estos son los requisitos mínimos exigibles para la seguridad. Si se omite cualquiera de ellos, se introduce un riesgo inaceptable en el sistema. Profundizamos en estos requisitos en nuestra publicación de blog sobre la seguridad del pentesting de IA.
Líneas base de seguridad como bloques de construcción de políticas
El Informe Internacional de Seguridad de la IA representa un progreso significativo hacia una comprensión compartida de los riesgos de la IA entre gobiernos, investigadores e industria. El desafío ahora es tender puentes entre los hallazgos de la investigación, los marcos regulatorios y las prácticas de implementación en el mundo real.
El informe plantea algunos escenarios de alto riesgo genuinos y estadísticas inquietantes sobre la rapidez con la que avanzan las capacidades. Dicho esto, esto no es motivo para entrar en pánico o regular la «IA» como un monolito aterrador. El propio informe señala que las salvaguardias varían ampliamente entre los desarrolladores y
que los mandatos prescriptivos pueden sofocar la innovación defensiva. Estamos de acuerdo. La regulación debería evitar imponer una única ruta de implementación. En su lugar, las políticas deberían definir líneas base de seguridad claras y orientadas a resultados que puedan servir como bloques de construcción para marcos más amplios.
Como parte del movimiento hacia la creación de marcos de seguridad más centrados en los resultados, hemos publicado nuestro documento sobre los Requisitos Mínimos de Seguridad para Pruebas de Seguridad impulsadas por IA. Para los equipos que evalúan herramientas de pentesting de IA o construyen sistemas de seguridad autónomos, esta guía sirve como referencia neutral para proveedores. Esperamos que esto ayude a los equipos a evaluar herramientas de pentesting de IA, construir sistemas de seguridad autónomos más seguros y contribuir al establecimiento de líneas base claras que funcionen tanto para desarrolladores como para reguladores.


