Las Pruebas de seguridad de aplicaciones estáticas (SAST) escanean tu código fuente — no la aplicación en ejecución — para encontrar patrones de codificación inseguros antes de que lleguen a producción. Es una de las herramientas de seguridad más tempranas y efectivas que puedes añadir a un flujo de trabajo de desarrollo porque detecta errores cuando son más baratos de corregir: mientras escribes código.
Qué hace realmente SAST
SAST analiza archivos fuente, buscando patrones que indiquen una vulnerabilidad: entradas de usuario no saneadas utilizadas en consultas SQL, criptografía inadecuada, flujos de autenticación inseguros, y más. Debido a que inspecciona el código de forma estática (sin ejecutarlo), SAST destaca por señalar prácticas de codificación inseguras en las primeras etapas del SDLC.
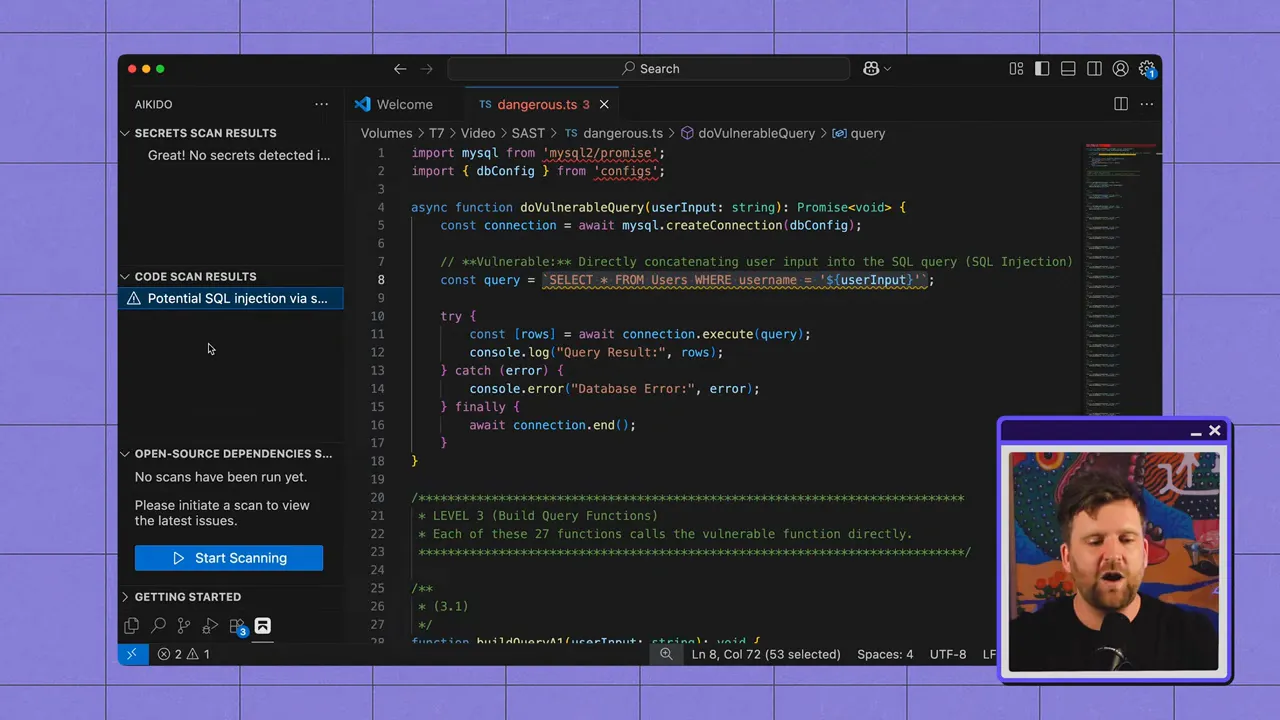
Donde SAST destaca
- Detección temprana: Se ejecuta en tu IDE o pipeline de CI, detectando errores antes de la fase de staging o producción.
- Cobertura basada en reglas: Los patrones inseguros conocidos (por ejemplo, fuentes/sumideros de inyección SQL) pueden detectarse de forma fiable con reglas bien escritas.
- Feedback amigable para desarrolladores: Las integraciones pueden mostrar los problemas en contexto para que los ingenieros puedan corregirlos de inmediato.
Sus límites
- Contexto de tiempo de ejecución limitado: SAST no puede determinar fácilmente si una ruta de código es alcanzable en producción, o cómo la configuración en tiempo de ejecución y las dependencias afectan el riesgo.
- Deficiente en fallos de lógica: Las vulnerabilidades de lógica de negocio y los problemas complejos de autorización son difíciles de detectar con reglas puramente estáticas.
- Puntos ciegos de dependencias y entorno: Las vulnerabilidades introducidas en tiempo de ejecución o a través de paquetes externos a menudo escapan al análisis estático.
Cómo SAST encuentra vulnerabilidades: reglas vs. IA
Las herramientas SAST tradicionales son predominantemente basadas en reglas: un motor analiza el código y aplica miles de reglas que coinciden con patrones inseguros conocidos. Este enfoque es eficiente y preciso para muchos tipos de fallos porque los patrones se comprenden bien.
“Cuando se trata de código estático, conocemos realmente los patrones que hacen que el código sea vulnerable.”
Algunos proveedores están impulsando la detección impulsada por IA, pero el escaneo LLM en bruto tiende a ser ruidoso y computacionalmente costoso — se aplica la famosa analogía: es como cortar el césped con un Ferrari. En cambio, el uso más efectivo de la IA hasta ahora no es el escaneo per se, sino añadir contexto a nivel de proyecto para mejorar el triaje y las sugerencias de corrección.
SAST de código abierto en la práctica: OpenGrep (un fork de Semgrep)
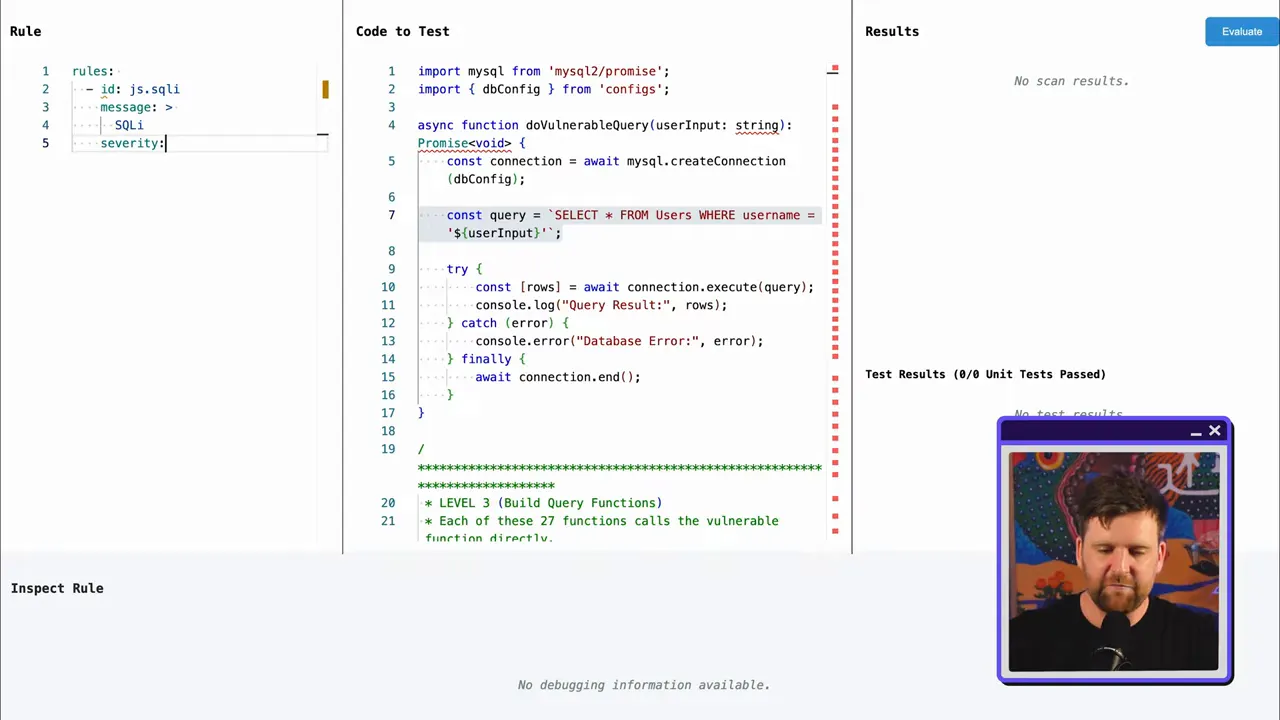
Las herramientas SAST de código abierto son excelentes puntos de partida porque separan el motor de escaneo del conjunto de reglas. El motor realiza el análisis sintáctico y la coincidencia; las reglas, a menudo mantenidas por la comunidad, definen cómo es lo “malo”.
Con un modelo de motor más reglas puede:
- Inspeccionar y personalizar reglas para su base de código.
- Escribir reglas específicas del proyecto para patrones únicos que los conjuntos de reglas comerciales no detectan.
- Compartir reglas personalizadas útiles con la comunidad para que su equipo y otros se beneficien.
Por qué los falsos positivos se convirtieron en un problema de reputación
El SAST basado en reglas a menudo abarca mucho. Esto es bueno para la detección —se encuentran más problemas potenciales—, pero también genera mucho ruido. Muchos problemas señalados no son accesibles en producción o son seguros en un contexto de proyecto particular, por lo que los equipos dedican tiempo a investigar alertas que no son relevantes.
Piensa en el SAST más antiguo como pescar con una red enorme: atraparás peces, pero también mucha basura. Alguien tiene que clasificarlo todo para encontrar lo que es valioso.
Donde la IA realmente ayuda al SAST: triaje automático y corrección automática
En lugar de reemplazar el escaneo basado en reglas, las herramientas SAST modernas combinan reglas estáticas con capas impulsadas por IA que añaden contexto y reducen el ruido:
- Triaje automático por IA: Los modelos de IA consumen los resultados de SAST y el contexto del proyecto para estimar la accesibilidad y el impacto en el mundo real. Priorizan los hallazgos que los desarrolladores realmente necesitan corregir primero (orientados a producción, rutas accesibles, problemas de alto impacto).
- Árboles de llamadas y accesibilidad: La IA puede construir un árbol de llamadas para una función señalada y mostrar dónde se originan las entradas y cómo fluyen los datos a través del repositorio, lo que facilita determinar si un problema es explotable.
- Sugerencias de corrección automática: La IA puede proponer correcciones de código concisas y accionables (p. ej., consultas parametrizadas en lugar de SQL concatenado con cadenas), lo que acelera la remediación dentro del IDE.

Dónde ejecutar SAST en tu flujo de trabajo de desarrollo
Para maximizar el valor, ejecuta SAST en múltiples etapas del SDLC:
- En el IDE: Los plugins del IDE detectan problemas mientras los desarrolladores escriben, lo que permite correcciones inmediatas y aprendizaje.
- En el repositorio remoto: Los escaneos en el repositorio proporcionan una única fuente de verdad para lo que se va a desplegar. Esto es esencial si se omitió o configuró incorrectamente un escaneo del IDE.
- En las pipelines de CI/CD: Los escaneos automatizados durante las compilaciones aplican puertas de política y evitan que el código inseguro avance a entornos de staging o producción.

Recomendaciones prácticas para equipos
- Empieza con código abierto: Utiliza una herramienta de la comunidad para saber qué encuentra SAST en tu base de código y genera confianza antes de adquirir herramientas comerciales.
- Personaliza las reglas: Añade reglas específicas del proyecto para patrones únicos de tu stack; comparte reglas útiles con la comunidad.
- Aplica la IA donde sea útil: Adopta la clasificación asistida por IA para reducir el ruido y la corrección automática para acelerar la remediación — pero no dependas de los LLM para el escaneo en bruto a gran escala hoy en día.
- Integra en tres puntos: IDE para la inmediatez del desarrollador, repositorio como fuente de verdad, CI para la aplicación.
- Mide y ajusta: Monitoriza la relación señal/ruido, ajusta los umbrales e itera sobre las reglas y los modelos de clasificación para que tu equipo confíe en el escáner.
Conclusiones finales
SAST sigue siendo una de las formas más rentables de reducir el riesgo de seguridad porque encuentra problemas a nivel de código de forma temprana. Los motores basados en reglas siguen siendo los pilares para la detección, mientras que la IA está demostrando ser muy valiosa como capa contextual que prioriza los hallazgos, explica la accesibilidad y propone soluciones.
Empieza poco a poco con SAST de código abierto para descubrir qué problemas existen en tu código. Cuando el ruido o la escala se conviertan en un problema, añade la clasificación asistida por IA y la corrección automática para llegar a una remediación real de vulnerabilidades — más rápido y con menos fricción para los desarrolladores. ¡Prueba Aikido Security hoy mismo!


