Introducción
Elegir la herramienta de seguridad de código adecuada puede determinar el éxito o fracaso de tu estrategia de seguridad de desarrollo. Snyk y Semgrep se comparan a menudo por su enfoque centrado en el desarrollador para encontrar vulnerabilidades en etapas tempranas. Ambos ayudan a los equipos a entregar código más seguro al integrar comprobaciones de seguridad en el desarrollo, pero cada uno tiene un enfoque diferente. Esta comparación explora cómo se posicionan y por qué la elección es crucial para los líderes técnicos responsables de la entrega segura de software.
TL;DR
Snyk y Semgrep ayudan a proteger tu base de código, pero se centran en capas diferentes, y ambos tienen puntos ciegos. Snyk destaca en el escaneo de dependencias de código abierto y contenedores, mientras que Semgrep se especializa en análisis estático de código. Aikido Security une ambos mundos en una única plataforma, con muchos menos falsos positivos y una integración más sencilla, lo que la convierte en la mejor opción para los equipos de seguridad modernos.
Comparativa de Snyk y Semgrep
Snyk
Snyk es una plataforma de seguridad centrada en el desarrollador conocida por encontrar vulnerabilidades en bibliotecas de código abierto y otros componentes. Comenzó con el análisis de composición de software (SCA) para detectar dependencias vulnerables, y más tarde se expandió al escaneo de imágenes de contenedores, infraestructura como código e incluso código estático a través de Snyk Code. La fortaleza de Snyk radica en su perfecta integración en los flujos de trabajo de desarrollo (como GitHub, pipelines de CI/CD e IDEs) para alertar a los desarrolladores sobre los riesgos de forma temprana. Enfatiza la seguridad 'shift-left', lo que lo hace popular entre los equipos ágiles de DevSecOps. Sin embargo, el enfoque amplio de Snyk conlleva compromisos en profundidad y ruido, que discutiremos.
Semgrep
Semgrep es una herramienta de análisis estático (SAST) de código abierto centrada en escanear tu código fuente en busca de errores y problemas de seguridad. Utiliza una coincidencia de patrones flexible y basada en reglas para detectar desde vulnerabilidades de seguridad hasta errores de calidad de código. Semgrep es ligero y consciente del lenguaje, lo que le permite ejecutarse rápidamente en pipelines de CI sin una configuración compleja. Su principal atractivo es la personalización: los equipos pueden escribir sus propias reglas en YAML para dirigirse a patrones específicos, lo que les da un gran poder para adaptar los escaneos a su base de código. Este diseño centrado en el desarrollador ha convertido a Semgrep en un favorito para aquellos que desean un control práctico sobre el escaneo de código. Pero el enfoque limitado de Semgrep (solo código) significa que no cubrirá por defecto las vulnerabilidades de paquetes de código abierto, contenedores o problemas de infraestructura, por lo que aborda solo una parte del rompecabezas de la seguridad.
Comparación de funcionalidades
Capacidades de escaneo de seguridad
Cobertura de Snyk: Snyk proporciona una amplia suite de capacidades de escaneo bajo un mismo paraguas. Es más fuerte en SCA (análisis de dependencias de código abierto), utilizando una base de datos de vulnerabilidades para señalar bibliotecas de riesgo en tu aplicación. Snyk también escanea imágenes de contenedores y configuraciones de IaC (Infraestructura como Código) en busca de problemas conocidos, con el objetivo de asegurar toda la pila. Además, Snyk Code ofrece análisis SAST para tu código, aunque esta es un área más reciente para Snyk y no su principal fortaleza. En la práctica, Snyk es más conocido por detectar vulnerabilidades conocidas (como esa biblioteca obsoleta con un CVE) y ayudar a los desarrolladores a solucionarlas a tiempo.
Cobertura de Semgrep: Semgrep, por el contrario, se centra exclusivamente en el análisis estático de código. Destaca en la detección de fallos de codificación, patrones inseguros y errores lógicos en tu propio código utilizando cientos de reglas escritas por la comunidad (y la opción de escribir reglas personalizadas). No tiene una base de datos integrada de CVEs para paquetes de código abierto ni escanea contenedores/IaC de forma predeterminada. (Semgrep tiene complementos separados como 'Semgrep Supply Chain' y 'Semgrep Secrets', pero son herramientas distintas en su ecosistema). El caso de uso principal es encontrar problemas en el propio código de la aplicación, por ejemplo, un uso inseguro de eval o una sanitización de entrada faltante, en lugar de vulnerabilidades en componentes de terceros. Esto significa que Semgrep puede descubrir errores de seguridad que el escáner de dependencias de Snyk podría pasar por alto, pero Semgrep pasará por alto cualquier cosa fuera del código (como una versión de biblioteca vulnerable o una imagen Docker mal configurada).
Diferencia clave: Snyk adopta un enfoque más amplio y centrado en componentes (código, dependencias, contenedores, configuración), mientras que Semgrep adopta un enfoque más profundo y centrado en el código. Si necesitas una herramienta para escanear tus paquetes de código abierto en busca de fallos conocidos, Snyk te cubre. Si te preocupa más el código personalizado que escribe tu equipo, el análisis estático de Semgrep es más directo. Ambas herramientas dejan lagunas: el análisis estático de código de Snyk no es tan exhaustivo como el de Semgrep, y Semgrep no ofrece cobertura para vulnerabilidades de la cadena de suministro por sí solo. Los líderes técnicos a menudo terminan usando múltiples herramientas o una plataforma combinada (como Aikido) para cubrir ambas bases.
Integración y Flujo de Trabajo DevOps
Integración de Snyk: Uno de los mayores puntos fuertes de Snyk es lo bien que se adapta a los flujos de trabajo existentes de los desarrolladores. Ofrece plugins para IDEs populares (para que los desarrolladores reciban alertas instantáneas mientras codifican), integraciones nativas con GitHub/GitLab/Bitbucket, y ganchos de pipeline de CI/CD que pueden fallar las compilaciones por problemas de seguridad. El servicio en la nube de Snyk monitorea tus repositorios; cada vez que abres una pull request o subes código nuevo, Snyk puede escanear y reportar problemas en la interfaz de usuario del proveedor de Git. Los desarrolladores aprecian que Snyk muestre los resultados justo donde trabajan, aunque una desventaja es que Snyk a menudo empuja a los usuarios a su panel web para obtener detalles, causando un cambio de contexto.
Cabe destacar que Snyk es una plataforma SaaS gestionada, lo que significa que tu código (o manifiesto de dependencias) se sube a su nube para su análisis. Esto facilita la configuración (sin servidores que mantener), pero algunas empresas se resisten a enviar código fuente al exterior, y la falta de opciones on-premise de Snyk puede ser un obstáculo para entornos altamente regulados. Además, Snyk principalmente soporta repositorios en la nube (si se utiliza la integración SCM de Snyk); cambios como renombrar un repositorio podrían incluso romper la conexión. En general, integrar Snyk es sencillo si ya trabajas en la nube y utilizas herramientas de desarrollo comunes. Es una solución 'plug and play' para equipos que practican DevSecOps, con la advertencia de que trabajarás dentro del ecosistema de Snyk.
Integración de Semgrep: El enfoque de Semgrep es más flexible y controlado por el desarrollador. Al ser de código abierto, puedes ejecutar el CLI de Semgrep localmente o en CI con mínimas complicaciones, sin necesidad de registrarte en un servicio si no quieres. Esto significa que puedes integrar los escaneos de Semgrep en cualquier lugar: un hook de pre-commit, un flujo de trabajo de GitHub Actions, un pipeline de Jenkins, lo que sea. Muchos equipos utilizan la acción oficial de Semgrep para GitHub o las integraciones de CI/CD para añadir comprobaciones de Semgrep en cada pull request, que luego dejan comentarios directamente en la revisión de código. Esta retroalimentación en línea (ver los problemas como comentarios en tu PR) facilita a los desarrolladores la corrección de problemas de código sin cambiar de contexto a otra aplicación.
Semgrep también tiene una plataforma SaaS opcional (Semgrep App) que agrega resultados, proporciona una interfaz de usuario y funciones de colaboración en equipo, similar a la interfaz de Snyk pero opcional. Es importante destacar que puedes ejecutar Semgrep completamente offline si es necesario, lo que atrae a equipos con requisitos estrictos de privacidad de código. La curva de aprendizaje para integrar Semgrep es baja para un uso básico (el CLI es sencillo), pero ajustarlo para tu entorno puede requerir escribir o seleccionar las reglas adecuadas, lo cual es un paso adicional que cubriremos en Precisión. En términos de dependencias de plataforma, Semgrep es agnóstico a la herramienta: no le importa qué sistema Git o CI uses, y no impone un alojamiento de repositorio particular (a diferencia, por ejemplo, de las soluciones solo para GitHub).
Esta flexibilidad hace que Semgrep sea adecuado para diversos flujos de trabajo, aunque con una configuración más manual en comparación con las integraciones 'click and go' de Snyk.
Precisión y Rendimiento
Falsos Positivos y Ruido: La precisión es un factor crítico para cualquier herramienta de seguridad; demasiados falsos positivos, y los desarrolladores empiezan a ignorar la herramienta. Aquí, tanto Snyk como Semgrep han recibido críticas, pero de diferentes maneras. El escaneo SAST (código) de Snyk tiene fama de tener altas tasas de falsos positivos en ciertos lenguajes. Los desarrolladores a menudo informan de ser inundados con hallazgos que no son vulnerabilidades reales, lo que puede erosionar la confianza en la herramienta. Una razón es que las reglas de Snyk son en su mayoría generalizadas y propietarias, dando a los usuarios visibilidad o control limitado para ajustarlas.
Si Snyk marca algo, puedes ignorarlo o parchearlo, pero no puedes ajustar fácilmente la lógica de la regla. Este enfoque de 'caja negra' a veces frustra a los equipos de seguridad cuando saben que un hallazgo no es un problema real pero siguen viéndolo marcado. Semgrep, por otro lado, también puede producir resultados ruidosos de forma predeterminada. Debido a que se basa en reglas de patrones, una ejecución de Semgrep sin ajustar puede marcar muchos problemas potenciales, incluyendo problemas menores de estilo o falsos positivos, dependiendo de los conjuntos de reglas que utilices. De hecho, usar Semgrep de manera efectiva a menudo requiere curar tus reglas para reducir el ruido; podrías empezar con un conjunto de reglas amplio y luego desactivar las reglas que no son relevantes o son demasiado ruidosas.
La ventaja es que tienes ese control: Semgrep proporciona visibilidad a nivel de regla y la capacidad de modificar o suprimir reglas específicas, por lo que con el tiempo los equipos pueden reducir significativamente los falsos positivos. En contraste, Snyk no te permite ajustar sus reglas integradas, lo que puede sentirse como un instrumento contundente en comparación.
Omisiones y Puntos Ciegos: La precisión no se trata solo de falsas alarmas; también se trata de lo que cada herramienta no logra detectar. Debido a que Snyk se basa en datos de vulnerabilidades conocidas para muchos de sus hallazgos, podría pasar por alto problemas de código personalizado que no tienen un CVE o una firma conocida. Snyk Code (su SAST) intenta encontrarlos, pero como se ha señalado, es un actor más reciente y podría no detectar errores lógicos complejos que Semgrep podría detectar con una regla bien escrita.
Por el contrario, Semgrep podría no reconocer que una determinada dependencia es vulnerable (a menos que hayas escrito una regla para detectar una cadena de versión o un patrón de uso específico), por lo que podría pasar por alto por completo un problema como 'actualiza esta biblioteca, tiene una vulnerabilidad RCE conocida'. Cada herramienta tiene puntos ciegos: Snyk puede pasar por alto ciertos problemas de flujo de datos o de calidad en el código, y Semgrep puede pasar por alto versiones de bibliotecas vulnerables o problemas de configuración por diseño.
Velocidad y Rendimiento: Ambas herramientas están diseñadas para ser relativamente rápidas y compatibles con CI, pero sus perfiles de rendimiento difieren. Los escaneos de Snyk, especialmente para dependencias, suelen ser rápidos (un escaneo de Snyk Open Source podría tardar segundos). El análisis de Snyk Code está basado en la nube y también puede devolver resultados en menos de un minuto para bases de código moderadas. Semgrep se ejecuta localmente (o en tu contenedor de CI) y es bastante ligero dada su exhaustividad; una base de código de ~50K líneas podría escanearse en uno o dos minutos. En pruebas de la comunidad, Semgrep fue ligeramente más lento que Snyk Code para el escaneo de código puro (por ejemplo, 90 segundos frente a 45 segundos en un repositorio de tamaño medio), pero aún así lo suficientemente rápido para CI en la mayoría de los casos.
Ambas pueden ejecutarse incrementalmente (escaneando solo el código modificado) para acelerar la retroalimentación en las pull requests. Cabe señalar que la ventaja de rendimiento de Snyk proviene en parte de los recursos en la nube que realizan el trabajo, mientras que la velocidad de Semgrep proviene de un motor ligero que no intenta realizar análisis inter-procedurales profundos como las herramientas SAST empresariales más pesadas. Ninguna de las herramientas impacta significativamente los tiempos de compilación cuando se configura correctamente, y ambas soportan la ejecución en paralelo con las pruebas. Si tu equipo valora la retroalimentación en tiempo real, el plugin de IDE de Snyk podría dar resultados instantáneos mientras escribes, mientras que el modelo de Semgrep es típicamente ejecutarse al guardar o hacer commit (aunque también tiene extensiones de IDE, son menos conocidas).
En resumen, ambas herramientas son lo suficientemente rápidas para un uso práctico, pero prepárate para invertir tiempo en ajustar Semgrep para evitar ahogarte en falsos positivos, y ten en cuenta que Snyk puede ocasionalmente marcar docenas de problemas que los desarrolladores tienen que revisar.
Cobertura y Alcance
Lenguajes y Frameworks: Snyk y Semgrep ambos presumen de soporte multi-lenguaje, pero su amplitud difiere. Snyk soporta muchos lenguajes para el escaneo de dependencias (básicamente cualquier lenguaje con un gestor de paquetes, desde npm de JavaScript hasta pip de Python o Maven de Java, etc.). Su SAST (Snyk Code) actualmente soporta lenguajes principales como Java, JavaScript/TypeScript, Python, C#, Ruby, PHP y algunos otros. Sin embargo, los usuarios han notado que la cobertura de reglas de Snyk varía según el lenguaje; el soporte de algunos ecosistemas aún está madurando.
Querrá verificar si Snyk cubre en profundidad los frameworks que utiliza (por ejemplo, puede manejar patrones comunes en Spring o Express, pero un lenguaje o framework más oscuro podría tener una cobertura más débil). Semgrep es compatible con una amplia gama de lenguajes para el escaneo de patrones – desde los más populares (JS/TS, Python, Java, C, Go, Ruby, etc.) hasta los más específicos como las configuraciones de Terraform y Kotlin. Dado que las reglas de Semgrep son impulsadas por la comunidad, la cobertura de lenguajes a menudo depende de la disponibilidad de las reglas. La ventaja es que si Semgrep no es compatible con un nuevo lenguaje de forma nativa, el equipo suele añadirlo rápidamente (o se pueden escribir patrones personalizados con una sintaxis limitada).
Para la mayoría de las pilas tecnológicas modernas, tanto Snyk como Semgrep serán compatibles con su lenguaje – pero Snyk podría no detectar todos los problemas específicos del framework hasta que sus reglas evolucionen, y Semgrep podría requerir que encuentre/escriba reglas para frameworks de vanguardia, ya que se basa en patrones.
Tipos de problemas: En cuanto a los tipos de problemas de seguridad cubiertos, Snyk es muy amplio para las vulnerabilidades conocidas – cubriendo no solo fallos de código, sino también problemas de configuración (como imágenes base de Docker inseguras o scripts de Terraform de AWS mal configurados) y fugas de secretos en el código. Es una solución integral para muchas categorías: SAST, SCA, escaneo de contenedores, escaneo IaC, e incluso cierto cumplimiento de licencias para código abierto. Sin embargo, esa amplitud puede diluir el enfoque: para patrones de vulnerabilidad de código realmente complejos, Snyk Code podría no tener una regla, mientras que una regla personalizada de Semgrep podría detectarlo. Las capacidades de detección de Semgrep se extienden a cualquier cosa que pueda codificar como un patrón.
De forma predeterminada, incluye reglas para los riesgos de aplicaciones web del Top 10 OWASP, credenciales codificadas, uso inseguro de criptografía y más. Pero, en particular, Semgrep no tiene conocimiento inherente de las bases de datos CVE o los benchmarks de contenedores; cualquier verificación para estos debe codificarse en una regla. En la práctica, la comunidad de Semgrep ha creado reglas para algunos patrones de dependencia vulnerables conocidos (por ejemplo, el uso de una API vulnerable en ciertas versiones de bibliotecas), pero esto no sustituye a una herramienta SCA dedicada. Si un líder técnico necesita cobertura en todo el SDLC (Ciclo de Vida de Desarrollo de Software) – desde el código hasta la nube – ni Snyk ni Semgrep por sí solos son suficientes. Snyk omite aspectos dinámicos/en tiempo de ejecución y cierta lógica de código profunda, mientras que Semgrep omite riesgos ambientales y de dependencia.
Aquí es donde entran en juego las plataformas combinadas o las múltiples herramientas. Por ejemplo, Aikido Security cubre tanto SAST como SCA en una sola plataforma para evitar esas brechas, proporcionando una cobertura más amplia que Snyk o Semgrep individualmente.
Lagunas notables: Para resumir las limitaciones del alcance: el enfoque de Semgrep es limitado – no escanea secretos, configuraciones de la nube, contenedores, etc., sin ayuda. El enfoque de Snyk es amplio pero superficial en el análisis de código – puede señalar muchos problemas de dependencia y configuración, pero pasar por alto algunas vulnerabilidades de código personalizado o producir información superficial. Además, Snyk tiene algunas limitaciones técnicas: por ejemplo, no escaneará archivos muy grandes (>1 MB) en el análisis de código, omitiéndolos silenciosamente, lo que podría dejar riesgos no detectados si tiene archivos de código auto-generados gigantes o archivos de datos en su repositorio. Semgrep no suele tener tales límites de tamaño de archivo, ya que usted controla qué escanear. En esencia, cada herramienta cubre lo que la otra omite: una realiza escaneo de código abierto y de entorno, la otra realiza escaneo de patrones de código. Superponer su cobertura requiere un esfuerzo de integración o el uso de una alternativa que unifique estos escaneos.
Experiencia del desarrollador
Facilidad de uso: Desde la perspectiva de un desarrollador, Snyk es muy fácil de usar para empezar – se registra, conecta un repositorio o ejecuta un comando CLI, y devuelve resultados con referencias sobre cómo solucionar los problemas. Su interfaz de usuario es pulcra, y los hallazgos a menudo enlazan a información adicional (como detalles de CVE o ejemplos de soluciones) lo que puede ser útil. El desarrollador recibe soluciones guiadas, especialmente para vulnerabilidades de código abierto – Snyk incluso puede abrir automáticamente una solicitud de extracción para actualizar la versión de una dependencia, lo cual es un buen detalle para equipos ocupados. Sin embargo, los desarrolladores se han quejado de que usar Snyk puede convertirse en un “whack-a-mole de vulnerabilidades”: se soluciona un problema, y el siguiente escaneo muestra más, a veces incluso volviendo a informar problemas que en realidad no lo son debido a la falta de contexto. Además, debido a que la información detallada de Snyk está en su plataforma, los desarrolladores deben salir de su entorno de código para iniciar sesión en el portal de Snyk para clasificar los problemas. Este cambio de contexto puede perjudicar la adopción – se siente como un proceso externo en lugar de parte de la codificación.
UX para desarrolladores de Semgrep: Semgrep adopta un enfoque más integrado para la experiencia del desarrollador. Cuando se configura para comentar en las solicitudes de extracción, los desarrolladores reciben feedback de seguridad en la propia revisión de código. Esto es mucho más inmediato y mantiene el flujo de trabajo de remediación junto con el flujo de trabajo de desarrollo. Los desarrolladores pueden discutir el hallazgo directamente en el PR, ajustar el código y enviar una solución, todo sin tener que ir a un panel de control separado. Además, los hallazgos de Semgrep suelen ser directos (“Esta línea parece un riesgo de inyección SQL, considere usar consultas parametrizadas”) porque las reglas pueden incluir mensajes personalizados.
Esta claridad y enfoque en contexto tienden a hacer que los desarrolladores estén menos a la defensiva; se siente más como feedback de revisión de código que como una auditoría externa. Por otro lado, Semgrep puede requerir que los desarrolladores se involucren en el ajuste de reglas o en el manejo de falsos positivos más de lo que lo harían con Snyk. La curva de aprendizaje para escribir una regla personalizada de Semgrep no es pronunciada (especialmente para ingenieros familiarizados con la codificación), pero es un trabajo adicional. Algunos desarrolladores también encuentran que la salida en bruto de Semgrep (si no se utiliza la integración de PR) es un poco ruidosa hasta que se configura. En cuanto a la interfaz de usuario, la aplicación Semgrep (si la usa) está mejorando, pero no es tan madura o completa como la interfaz de Snyk para el seguimiento de problemas en todos los proyectos. Es minimalista por diseño – encajando con la filosofía de ir al grano – pero para equipos más grandes, aspectos como el seguimiento del flujo de trabajo, la asignación y las métricas históricas están menos desarrollados.
Un líder técnico podría señalar que Snyk ofrece más informes “empresariales” (paneles de control, informes de cumplimiento, etc.), mientras que Semgrep se centra en entregar alertas a los desarrolladores de manera oportuna. Esta es una diferencia filosófica: Snyk intenta ser una plataforma integral (con paneles para gerentes), mientras que Semgrep prioriza la integración y flexibilidad del flujo de trabajo del desarrollador sobre los paneles de control sofisticados.
Automatización y soluciones: Ambas herramientas están evolucionando en cómo ayudan a remediar los problemas. Snyk proporciona solicitudes de extracción de corrección automatizadas para problemas de dependencia y mostrará ejemplos de soluciones para problemas de código (a menudo solo un fragmento de su base de conocimientos). Semgrep ha introducido Semgrep Autofix/Assistant, que utiliza IA para proponer cambios de código reales para ciertos hallazgos. Por ejemplo, si Semgrep encuentra un uso peligroso de eval, el asistente podría sugerir un fragmento de código más seguro para reemplazarlo. Los primeros comentarios indican que esto puede ahorrar tiempo a los desarrolladores, aunque no es perfecto. El enfoque de Snyk es más tradicional – no cambia automáticamente su código (aparte de las dependencias) pero ofrece orientación.
Dependiendo de las preferencias de sus desarrolladores, podrían preferir el intento de Semgrep de auto-correcciones, o podrían preferir las referencias explícitas de Snyk. Manejo de falsos positivos: Una nota más sobre la experiencia del desarrollador: cuando un hallazgo no es realmente un problema, ¿con qué facilidad se puede descartar? En Snyk, puede marcar elementos como ignorados (con opciones de caducidad), pero si la regla se activa en un código ligeramente diferente, lo volverá a ver.
En Semgrep, dado que puede modificar o desactivar la regla por completo, tiene una solución más permanente (aunque debe tener cuidado de no desactivar algo real). Los desarrolladores que odian ver la misma falsa alarma repetidamente podrían apreciar que Semgrep aprende de los comentarios (cuando marca un hallazgo como falso, puede ajustar la regla para dejar de señalar ese patrón). Con Snyk, los desarrolladores a veces sienten que están atrapados con las peculiaridades de la herramienta y tienen que convivir con ciertos no-problemas o filtrarlos manualmente cada vez.
Precios y Mantenimiento
Precios de Snyk: Snyk es un SaaS comercial con un modelo de precios por niveles. Ofrece un nivel gratuito para proyectos de pequeña escala o de código abierto (con algunos límites en el número de pruebas), pero el uso serio a nivel de equipo o empresarial requiere un plan de pago. Snyk suele cobrar por puesto de desarrollador (y posiblemente por proyecto para ciertos productos), lo que puede resultar caro a medida que se amplía el equipo de ingeniería. Las organizaciones a menudo descubren que a medida que integran Snyk en docenas de repositorios y desarrolladores, la factura aumenta considerablemente, lo que a veces les lleva a escanear selectivamente solo los repositorios críticos para controlar los costes. El plan empresarial de Snyk añade características como informes SLA personalizados y soporte on-premise (en casos raros), pero estos tienen un coste adicional. En resumen, Snyk puede ser una de las herramientas más caras en este ámbito, y presupuestar para ello es una consideración para un líder de seguridad.
Precios de Semgrep: El núcleo de Semgrep es de código abierto y de uso gratuito. Esto significa que puede ejecutar escaneos ilimitados a través de CLI o CI sin pagar un céntimo, lo cual es una gran ventaja para los equipos con un presupuesto ajustado. La empresa detrás de Semgrep sí ofrece planes empresariales de pago (Semgrep Team/Enterprise) que incluyen una aplicación en la nube gestionada, bibliotecas de reglas adicionales y soporte. Esos planes también suelen tener un precio por puesto (es decir, por desarrollador o por puesto de proyecto). Aun así, dado que tiene la libertad de usar la versión gratuita, los equipos a menudo comienzan con Semgrep Community Edition y solo consideran pagar si necesitan la comodidad de la plataforma centralizada o las funciones avanzadas.
El mantenimiento, sin embargo, es un coste con Semgrep – la sobrecarga operativa de gestionar reglas y herramientas. En lugar de una suscripción, se dedica tiempo de ingeniería a mantener las reglas actualizadas y a clasificar los hallazgos. Para un equipo pequeño con pocos repositorios, este coste es insignificante. Pero para una organización más grande, mantener un gran conjunto de reglas y supresiones personalizadas de Semgrep puede convertirse en un esfuerzo considerable. Algunas empresas mitigan esto utilizando los paquetes de reglas de la comunidad y contribuyendo, subcontratando eficazmente parte del mantenimiento a la comunidad. Aun así, es importante tener en cuenta que Semgrep no es “gratuito” si se cuenta el tiempo de ingeniería necesario para ajustarlo a escala.
Mantenimiento e infraestructura: Con Snyk, el mantenimiento de la infraestructura es mínimo – es un SaaS en la nube, por lo que no se mantienen servidores (a menos que opte por un dispositivo on-premise para Snyk, lo cual es poco común y puede incurrir en costes adicionales). Sí necesita gestionar la integración (asegurándose de que cada repositorio esté vinculado, cada pipeline tenga el paso de Snyk, etc.) y mantener la CLI actualizada si la usa allí. Snyk se encarga de actualizar las bases de datos de vulnerabilidades y mejorar las reglas por su parte (a veces esas actualizaciones también pueden introducir nuevos hallazgos de la noche a la mañana). Semgrep, cuando se autoaloja, requiere que mantenga la CLI actualizada (lo cual es tan simple como una instalación de pip o una descarga binaria en CI).
Si utiliza la aplicación Semgrep, es SaaS y ellos la mantienen, pero aún podría alojar una implementación interna si lo prefiere (lo que requiere un servidor y cierta configuración). En general, el mantenimiento de Semgrep se centra más en el contenido (reglas) que en la herramienta en sí.
Transparencia de precios: Cabe señalar que los precios empresariales tanto de Snyk como de Semgrep pueden ser un poco complejos. Snyk a menudo negocia acuerdos empresariales personalizados, y los precios de Semgrep para el nivel de pago no se publican, lo que generalmente requiere contactar para obtener un presupuesto. Aquí es donde Aikido Security se diferencia: Aikido ofrece un modelo de precios más simple y plano que no le penaliza por añadir más proyectos o desarrolladores. Tiende a ser más predecible y asequible a escala en comparación con los costes por puesto de Snyk o los planes de pago de Semgrep.
Pros y contras de cada herramienta

Ventajas de Snyk:
- Amplia cobertura de seguridad: Escanea código, dependencias de código abierto, contenedores, archivos de configuración y más en una sola plataforma, proporcionando una amplia red de seguridad.
- Integración amigable para desarrolladores: Fácil de integrar en repositorios, CI/CD e IDEs para un escaneo automatizado y feedback rápido en los flujos de trabajo de desarrollo.
- Soluciones accionables para dependencias: Proporciona una guía clara de actualización e incluso pull requests automáticas para corregir librerías vulnerables, simplificando la remediación de problemas de SCA.
- Interfaz de usuario intuitiva: Panel de control pulido con detalles de vulnerabilidades, sugerencias de priorización y enlaces a información adicional, lo cual es útil para los desarrolladores que aprenden a solucionar problemas.
Desventajas de Snyk:
- Altos falsos positivos en SAST: Su análisis estático de código a menudo marca muchos no-problemas, causando fatiga de alertas entre los desarrolladores.
- Análisis de código superficial: Fuerte en la detección de CVE conocidos, pero más débil en la búsqueda de errores complejos en código personalizado (sin análisis avanzado de flujo de datos o en tiempo de ejecución como algunas herramientas SAST).
- Costoso a escala: El precio por desarrollador puede volverse elevado para equipos grandes, y las características avanzadas están bloqueadas en planes empresariales.
- Personalización limitada: Reglas de código cerrado sin capacidad para ajustar la lógica de detección; debes esperar actualizaciones del proveedor o usar mecanismos de ignorar poco prácticos si algo está fallando.
- Posible fricción de integración: Requiere subir datos a un servicio en la nube (lo que algunas organizaciones no pueden permitir), y la plataforma puede omitir el escaneo de archivos grandes o de ciertos archivos sin previo aviso claro.

Ventajas de Semgrep:
- Análisis estático potente: Excelente para detectar vulnerabilidades de código y anti-patrones con reglas ligeras, cubriendo muchos lenguajes y frameworks.
- Altamente personalizable: Los ingenieros de seguridad pueden escribir reglas personalizadas en YAML para apuntar a los patrones relevantes para su base de código. Esta flexibilidad permite encontrar problemas únicos de su aplicación que las herramientas genéricas pasarían por alto.
- Rápido y ligero: Se ejecuta rápidamente en pipelines de CI con un impacto mínimo en los tiempos de compilación, y no requiere infraestructura pesada ni recursos en la nube para operar.
- Flujo de trabajo centrado en el desarrollador: Se integra en pull requests y herramientas de desarrollo, proporcionando retroalimentación inmediata y en contexto que los desarrolladores encuentran útil (se siente como parte de la revisión de código en lugar de un escáner externo).
- Código abierto y transparente: El motor de escaneo y muchos conjuntos de reglas son abiertos, permitiendo a los equipos una visibilidad completa de las comprobaciones que se realizan y la capacidad de ajustarlas o extenderlas. Sin cajas negras.
Desventajas de Semgrep:
- Enfoque limitado: Solo cubre código (SAST). Carece de escaneo integrado para vulnerabilidades de dependencias de código abierto, secretos, contenedores o IaC, por lo que aborda una porción limitada del espectro de seguridad. Los equipos necesitarán herramientas adicionales para una cobertura completa.
- Ruidoso sin ajuste: Los conjuntos de reglas predeterminados pueden producir muchos hallazgos, incluidos falsos positivos, lo que requiere un ajuste inicial para filtrar reglas irrelevantes y reducir el ruido. Este ajuste exige experiencia en seguridad y una adaptación continua a medida que el código evoluciona.
- Sobrecarga de mantenimiento: Gestionar una gran biblioteca de reglas personalizadas y mantenerlas actualizadas a medida que cambian la base de código y el panorama de amenazas es un esfuerzo continuo. A escala empresarial, esto puede volverse oneroso sin ingenieros de AppSec dedicados.
- Contexto y priorización limitados: Los hallazgos se basan en coincidencias de patrones sin un contexto más amplio (por ejemplo, si el código vulnerable es realmente accesible o explotable en tiempo de ejecución). Esto puede resultar en una larga lista de problemas sin orientación sobre cuáles son realmente importantes, a diferencia de las herramientas que incorporan el contexto de riesgo.
- Menos características empresariales: Carece de algunas de las características de gobernanza, informes y cumplimiento que las organizaciones más grandes podrían desear (por ejemplo, registros de auditoría, acceso basado en roles, comprobaciones de cumplimiento preconfiguradas). Semgrep está mejorando en este aspecto, pero su enfoque principal sigue siendo empoderar a los desarrolladores en lugar de satisfacer a los auditores.
Aikido Security: La mejor alternativa
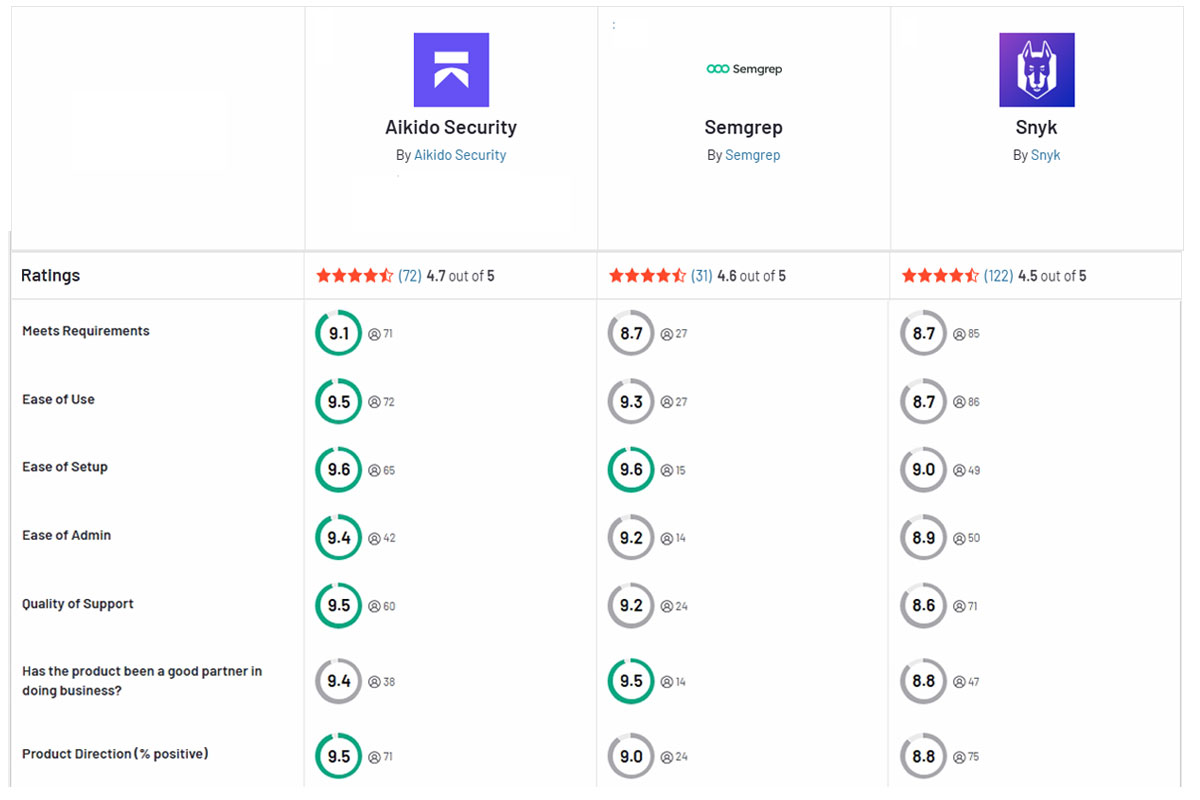
Los equipos de seguridad modernos a menudo necesitan las fortalezas de Snyk y Semgrep sin los dolores de cabeza. Aikido Security fue construido como una solución unificada que combina el escaneo de código y el análisis de dependencias en una plataforma amigable para desarrolladores. Cubre SAST y SCA juntos, para que no te veas obligado a hacer malabarismos con múltiples herramientas.
Al reunir múltiples tipos de escaneo en un solo lugar, Aikido puede contextualizar las vulnerabilidades y filtrar los falsos positivos – reduciendo el ruido hasta en un 95%. Menos falsas alarmas significan que los desarrolladores realmente confían en los hallazgos. La integración es perfecta: Aikido se conecta a tus repositorios y pipelines como Snyk, pero también entrega resultados en línea como Semgrep, minimizando la fricción. Las ventajas clave provienen de la automatización inteligente – por ejemplo, correcciones y priorización impulsadas por IA – ahorrando tiempo a tu equipo.
A diferencia de los proveedores tradicionales, Aikido mantiene las cosas claras y transparentes. El precio es fijo y predecible, evitando los altos costes por puesto que hacen que Snyk o Semgrep sean caros a escala. En resumen, Aikido une ambos mundos en una sola plataforma con mucho menos ruido y complejidad, lo que la convierte en una mejor opción para los equipos que desean seguridad efectiva sin la fatiga de herramientas habitual.
Inicia una prueba gratuita o solicita una demostración para explorar la solución completa.


